· Jakub · CI/CD · 6 min read
Scalable Ephemeral GitHub Actions Runners on AWS Spot Instances with Terraform
How I delivered a cost-optimized, auto-scaling GitHub Actions runner fleet on AWS using spot instances, pre-built AMIs, and time-based pool scheduling — eliminating idle compute costs for a SaaS client.
Introduction
GitHub-hosted runners are convenient until they aren’t. For a client running a multi-repo SaaS monorepo with heavy build workloads — Java, Angular, Docker — the cost and queue latency of shared GitHub runners became a bottleneck. Jobs waited. Costs scaled linearly with usage.
The goal was clear: self-hosted runners on AWS that scale to zero when idle, burst on demand, and cost as little as possible during off-hours — without sacrificing reliability or developer experience.
I delivered a fully automated, ephemeral GitHub Actions runner fleet using AWS EC2 spot instances, Lambda-based webhook processing, pre-baked AMIs, and time-aware pool scheduling. The entire stack is managed by Terraform.
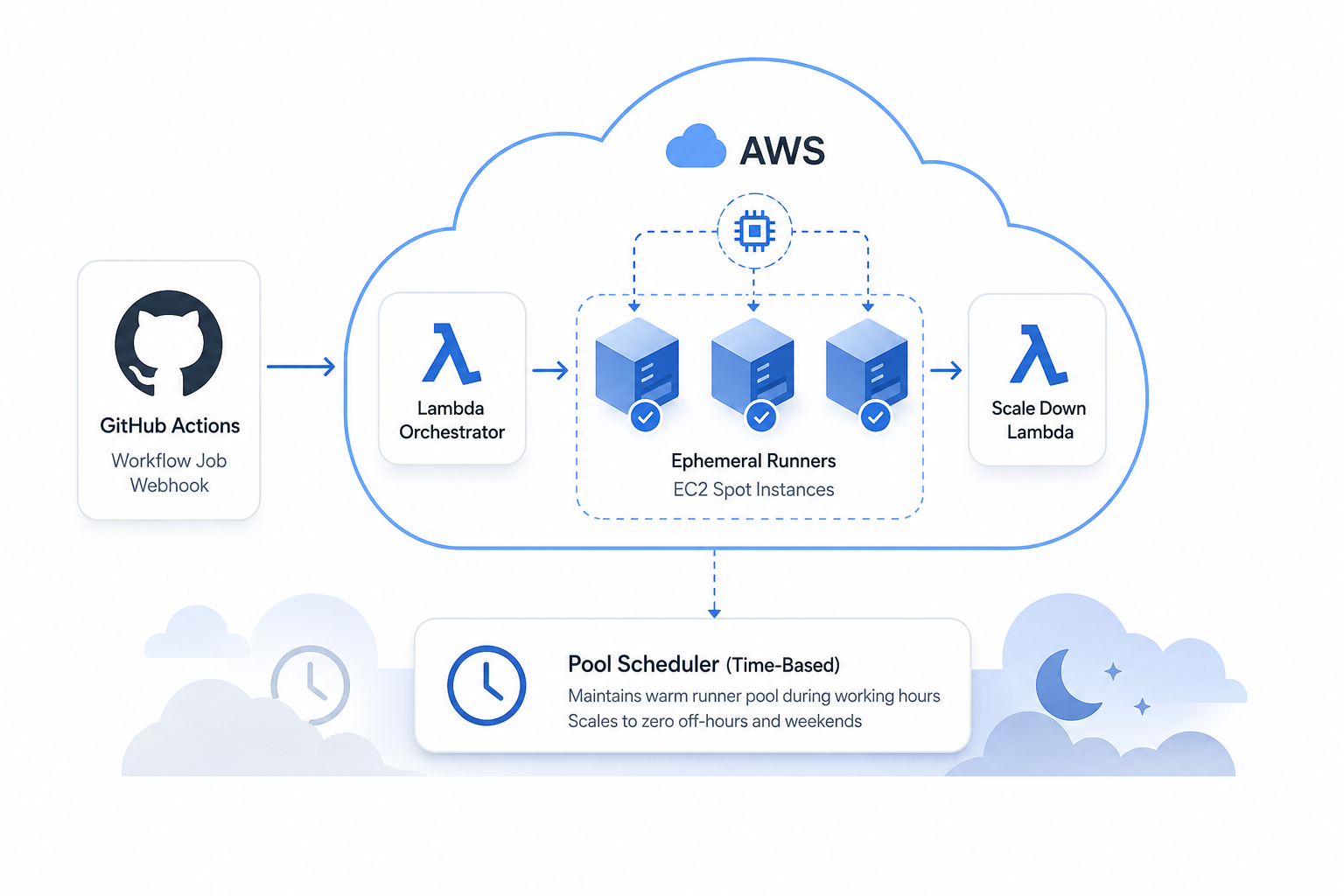
System Architecture
The solution is built on the github-aws-runners/github-runner Terraform module, wrapped with environment-specific configuration and a custom pre-built AMI layer.
At a high level, the system has four components:
- GitHub App — receives workflow job webhook events and forwards them to an AWS API Gateway endpoint.
- Lambda fleet — three functions handle webhook ingestion, runner lifecycle management, and binary syncing.
- EC2 spot runners — ephemeral instances launched on demand, registered as organization-level GitHub runners, and terminated after job completion.
- Pool scheduler — a cron-driven Lambda that maintains a warm runner pool during defined working hours.
The base infrastructure (VPC, subnets) is managed separately and consumed as a module dependency, keeping the runner stack focused on compute concerns.
Runtime & Scaling Behavior
Webhook-Driven Burst Scaling
When a GitHub Actions job is queued, the GitHub App fires a webhook. A Lambda processes the event and, if no runner is available, provisions a new EC2 spot instance within seconds. The delay_webhook_event is set to 0 — no artificial delay before a runner is started.
The job queue retains events for 600 seconds. A dead-letter redrive is configured with a maxReceiveCount of 50, ensuring transient failures in Lambda or spot capacity don’t silently drop jobs.
delay_webhook_event = 0
job_queue_retention_in_seconds = 600
redrive_build_queue = {
enabled = true
maxReceiveCount = 50
}Pool Scheduling
Rather than relying entirely on reactive scaling, I configured a time-aware pool that maintains warm runners during business hours. This eliminates cold-start latency for developers working within predictable windows.
The pool configuration spans four time bands:
| Window (UTC) | Days | Pool Size |
|---|---|---|
| 05:00–16:00 | Mon–Sat | 3 |
| 16:00–20:00 | Mon–Sat | 1 |
| 03:00–05:00 | Mon–Sat | 1 |
| 20:00–03:00 | Mon–Sat | 0 |
| All day | Sunday | 0 |
Off-peak and weekend periods drop to zero — no idle spend.
Scale-Down Cadence
Runners are ephemeral by design. Every minute, a scale-down Lambda evaluates idle instances and terminates them. Combined with a minimum_running_time_in_minutes of 10, this prevents spot instances from being terminated before their minimum billing unit is consumed.
enable_ephemeral_runners = true
scale_down_schedule_expression = "cron(* * * * ? *)"
minimum_running_time_in_minutes = 10Key Engineering Decisions
Pre-Built AMI Over User Data
Boot time is the primary latency factor in reactive runner scaling. Instead of bootstrapping runners at launch via user data, I built a custom AMI using Packer on Amazon Linux 2023.
The AMI bakes in everything the client’s pipelines need:
- Docker + Docker Compose + Buildx
- Java 17 (Amazon Corretto)
- Node 20 via NVM + Angular CLI
- Maven via SDKman
- GitHub CLI + AWS CLI v2
- A pre-populated local Maven repository (
~/.m2/repository)
The Maven repository is particularly impactful. Dependency resolution is the dominant cost in Java build times. By baking the repository into the AMI, cold builds behave like warm builds.
The start-runner.sh script is embedded into the AMI at /var/lib/cloud/scripts/per-boot/, so no extra user data injection is needed at launch time.
Spot Instance Fleet Diversity
To minimize spot interruption risk, I configured a diverse instance type pool across three families:
instance_types = [
"t3.medium", "t3.large",
"t2.medium", "t2.large",
"t3a.medium", "t3a.large"
]
instance_target_capacity_type = "spot"AWS will select the most available type from the list at launch time. This significantly reduces the probability of capacity unavailability in eu-central-1.
Organization-Level Runner Registration
Runners are registered at the GitHub organization level rather than per-repository. This means any repository in the organization can consume capacity from the same pool, improving utilization and eliminating per-repo configuration overhead.
SSM Access Without Bastion
All runners have SSM access enabled. This provides secure shell access for debugging without exposing SSH or maintaining a bastion host.
Trade-offs
Optimized for: cold-start latency, cost at scale, operational simplicity.
Sacrificed:
- AMI freshness — baking dependencies into the image means periodic AMI rebuilds are required to pick up package updates or toolchain version bumps. The manifest tracks 19 builds to date, so this is an established operational pattern, not an afterthought.
- Runner binary syncer disabled —
enable_runner_binaries_syncer = falsemeans the GitHub Actions runner binary is baked into the AMI. This trades automatic binary updates for faster boot times. Runner version (2.328.0) must be updated manually by triggering a new AMI build. - Spot interruption — the 10-minute minimum runtime mitigates billing waste, but a spot interruption mid-job will fail the workflow. The job queue redrive partially compensates, but this is an accepted trade-off for cost savings.
Cost & Operational Impact
The primary cost levers are:
- Spot pricing for t3/t2/t3a instances is typically 60–70% below on-demand.
- Scale-to-zero on weekends and off-hours eliminates idle compute entirely.
- Pre-built AMI reduces runner uptime per job, shrinking per-job spot cost.
- Maximum runner cap of 40 provides a hard ceiling on runaway spend during unexpected CI spikes.
Monthly Cost Comparison
To put the economics in context, here’s a rough comparison for a team running ~5,000 CI minutes per month (moderate SaaS workload):
| Platform | Plan / Tier | Included Minutes | Overage Rate | Est. Monthly Cost |
|---|---|---|---|---|
| GitHub Actions | Team ($4/user/mo) | 3,000/mo (Linux) | $0.008/min | ~$90 (10 users + overage) |
| GitHub Actions | Enterprise | 50,000/mo | $0.008/min | ~$420+ (50 users) |
| GitLab CI | Premium ($29/user/mo) | 10,000 shared | $0.005/min | ~$300 (10 users) |
| Bitbucket Pipelines | Standard ($3/user/mo) | 2,500 build min | $0.005/min | ~$55 (10 users + overage) |
| This solution (AWS Spot) | Pay-as-you-go | Unlimited | ~$0.001–0.002/min | ~$15–30 |
Estimates assume
eu-central-1spot pricing fort3.large(~$0.022/hr) and average job duration of 8 minutes. Actual costs vary by region and spot market conditions.
For a team running heavy workloads — 30,000–50,000 minutes/month (the client’s actual usage) — the difference compounds dramatically:
| Platform | Est. Monthly Cost at 40,000 min |
|---|---|
| GitHub Actions (Team) | ~$370 |
| GitLab CI (Premium) | ~$150+ |
| Bitbucket Pipelines | ~$190 |
| This solution (AWS Spot) | ~$60–90 |
The spot fleet, pool scheduling, and scale-to-zero on weekends are the primary cost levers. A comparable fleet running 24/7 on on-demand instances would cost roughly 3–4× more than the spot configuration.
What’s Not Free
This solution trades SaaS convenience for cost efficiency. The additional overhead includes:
- AWS Lambda invocations — negligible at this scale (
<$1/month) - SQS queues — effectively free at job volumes under 1M messages/month
- AMI storage (S3 + EBS snapshots) — ~$3–5/month for 19 build manifests
- Engineering time — initial setup is 2–3 days; ongoing maintenance is ~1 hour/month for AMI rebuilds
Total infrastructure overhead adds ~$5–10/month on top of compute costs — still well below any SaaS runner tier at this job volume.
The primary cost levers are:
- Spot pricing for t3/t2/t3a instances is typically 60–70% below on-demand.
- Scale-to-zero on weekends and off-hours eliminates idle compute entirely.
- Pre-built AMI reduces runner uptime per job, shrinking per-job spot cost.
- Maximum runner cap of 40 provides a hard ceiling on runaway spend during unexpected CI spikes.
Operationally, the system is largely self-managing. The only recurring maintenance task is rebuilding the AMI when toolchain versions change — a packer build invocation followed by updating the ami_name variable and running terraform apply.
Conclusion
This architecture demonstrates that self-hosted GitHub Actions runners don’t have to be operationally complex. By combining ephemeral spot instances, a time-aware pool, and a dependency-rich pre-built AMI, it’s possible to achieve sub-60-second runner availability at materially lower cost than GitHub-hosted alternatives — with full control over the toolchain.
The system is fully declarative, auditable through version-controlled Terraform state, and requires minimal ongoing intervention.
If you’re working on similar CI/CD infrastructure challenges or evaluating self-hosted runner strategies for your platform, feel free to reach out at hello@jakops.cloud.