· Jakub · Platform Engineering · 9 min read
Migrating a Terraform Monolith to Terragrunt: State Slicing Without Downtime
How I decomposed a monolithic Terraform state into isolated Terragrunt modules for a SaaS client — without touching live infrastructure.
Introduction
At some point, every SaaS platform that started with “just Terraform” hits the same wall. The state file grows. Plans slow down. A change to a load balancer rule triggers a full re-evaluation of the RDS cluster, the Kubernetes node groups, the S3 buckets — everything. Engineers start avoiding applies. Reviews get skipped because “it’s probably fine.” The monolith becomes a bottleneck, then a liability.
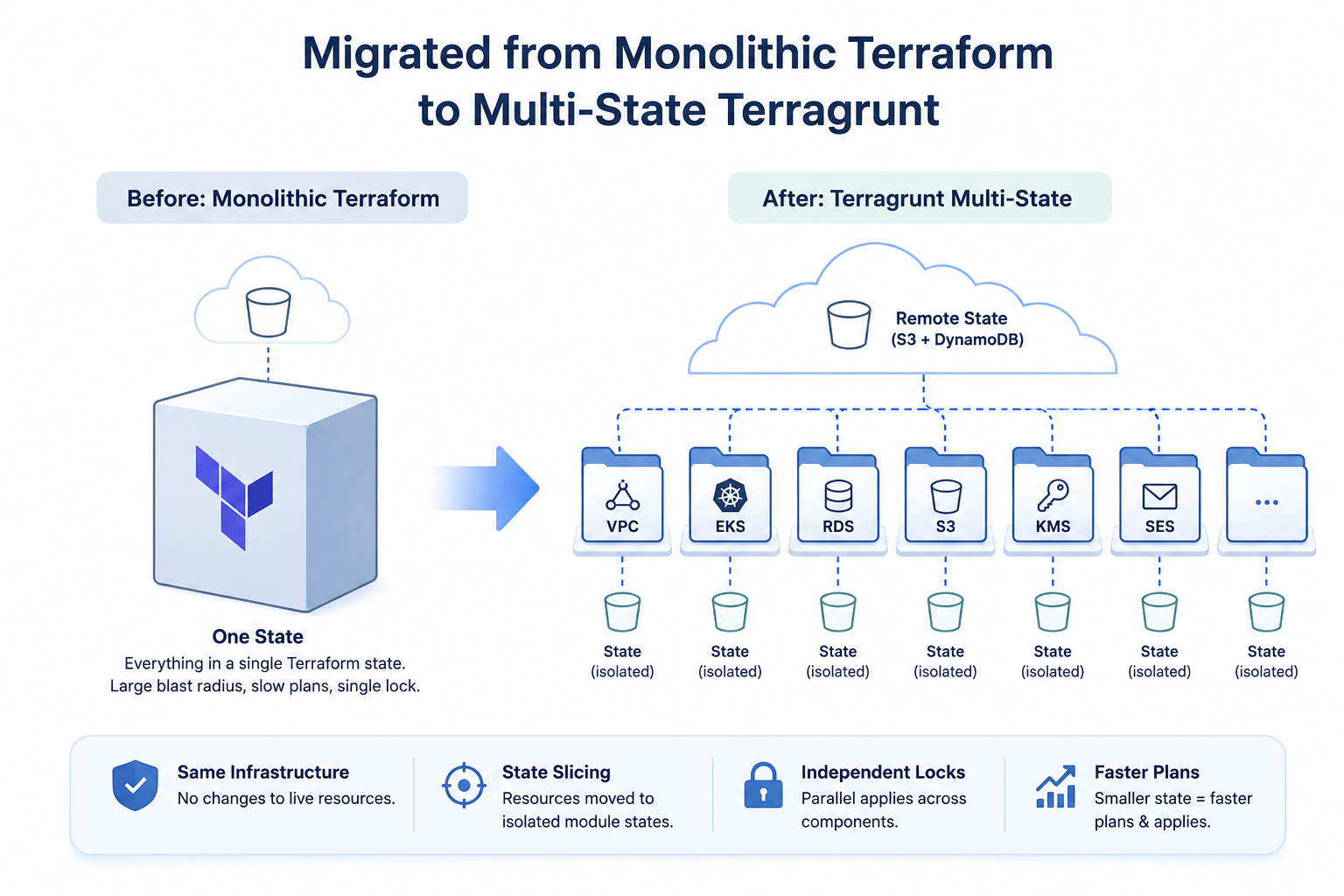
I was engaged by a client running a multi-component AWS platform — VPC, EKS, RDS (two instances), ElasticSearch, SES, KMS, SSM, S3, ACM certificates, a bastion host, three frontend distributions, and Kubernetes/ElasticSearch deployment layers. Every one of these components lived inside a single nested Terraform module structure under one top-level module, backed by one remote state in S3.
The goal: decompose it into a Terragrunt monorepo with isolated state per component, clean inter-module dependency wiring, and zero infrastructure changes — zero downtime, zero drift.
Why This Migration Was Necessary
The technical case is straightforward, but it’s worth being explicit about what the monolith actually costs at this scale:
Blast radius. A single state means a single lock. One engineer applying a Kubernetes change blocks everyone else from touching RDS, S3, or anything else. In a team with parallel workstreams, this is a constant source of friction.
Plan performance. Terraform has to reconcile every resource on every plan. With 19 logical infrastructure components — some deeply nested with count and for_each — plan times were long enough to discourage iterative development.
Refactoring risk. Moving a resource address inside a monolith risks touching adjacent resources in the same state. The change surface is the entire infrastructure.
Lack of ownership boundaries. When everything is in one state, there’s no natural way to say “the networking team owns VPC, the app team owns Kubernetes deployments.” Terragrunt modules with isolated state create those boundaries explicitly.
Output coupling. The monolith passed values between logical components via Terraform locals and module references. In Terragrunt, those become explicit dependency blocks with typed outputs — versioned, inspectable, and independently cacheable.
The migration was not optional. It was a prerequisite for the client’s team to scale their infrastructure workflow.
The Starting Point: Module Structure in the Monolith
The monolith organized everything under a two-level module hierarchy — a top-level environment module wrapping 13 child modules, one per infrastructure concern:
module.client_stage
└── module.vpc
└── module.kubernetes
└── module.database
└── module.elasticsearch
└── module.ses
└── module.kms_key
└── module.ssl_certificate
└── module.ssm
└── module.s3
└── module.bastion_host
└── module.frontend
└── module.password_protection
└── module.deployment_kubernetesEach of these maps 1:1 to a Terragrunt module directory. The state slicing task was to take every resource living under module.client_stage.module.<name>.* and move it into the corresponding module’s own local state file, with addresses rewritten to drop the parent prefix.
Migration Strategy
The migration had one hard constraint: no infrastructure changes. The state had to be recut — not re-created.
Step 1 — Pull the Monolith State Locally
terraform state pull > monolith.tfstateA point-in-time snapshot of the full state, written to disk. This becomes the immutable source for all slicing operations. Working against a local file means the remote state is never modified during the migration — no risk of partial writes or corrupted remote state mid-process.
Step 2 — Run the State Migration Script
This is where the actual work happens. Rather than running terraform state mv commands by hand — error-prone at this scale — I wrote a script that automated the full slicing process.
The script operates in four logical phases:
Phase 1: Load and enumerate. The monolith state file is passed to terraform state list, producing a flat list of every resource address. The script immediately validates this list is non-empty before proceeding.
STATE_LIST=$(terraform state list -state="$MONOLITH_STATE")Phase 2: Discover child modules dynamically. Rather than hardcoding which modules exist in the state, the script extracts unique direct child module names by parsing the resource list:
DIRECT_MODULES=$(echo "$STATE_LIST" | grep "^${MODULE_PREFIX}\.module\." | \
sed "s|^${MODULE_PREFIX}\.module\.||" | \
sed 's/^\([^.[]*\).*/\1/' | sort -u)This strips the top-level prefix and collapses indexed entries (e.g., ses[0] → ses), giving a clean list of logical module names. Discovering dynamically rather than hardcoding means the script won’t silently miss modules that exist in state but aren’t in a static inventory.
Phase 3: Map modules to directories. A case statement maps each logical module name to its Terragrunt directory:
get_stack_dir() {
case "$1" in
client_database) echo "rds" ;;
client_kubernetes) echo "kubernetes" ;;
client_ssl_certificate) echo "certificate" ;;
# ...
esac
}This is the human-maintained mapping layer — the only place where intent is encoded rather than derived. Getting this wrong means resources land in the wrong module state, which Terraform surfaces immediately on the subsequent plan as unexpected additions or deletions.
Phase 4: Rewrite addresses and move resources. For each resource in the state list, the script matches it against the current module prefix using both dot-separated and bracket-indexed patterns — correctly handling resources from indexed modules like module.ses[0].aws_s3_bucket.this:
if [[ "$resource" == ${MODULE_PREFIX}.module.${module_name}.* ]] || \
[[ "$resource" == ${MODULE_PREFIX}.module.${module_name}[* ]]; thenThen a Python one-liner strips the full parent prefix from the address, leaving only the root-relative address as the target module expects it:
pattern = r'^module\.client_stage\.module\.[^.\[]+(\[[^\]]*\])?\.(.+)$'
m = re.match(pattern, line)
print(m.group(2) if m else line)A concrete example of what this transformation looks like:
# Before (address in monolith state)
module.client_stage.module.database.module.rds.aws_db_instance.this[0]
# After (address in the isolated rds/ module state)
module.rds.aws_db_instance.this[0]The move itself writes to a per-module local state file without modifying the source:
terraform state mv \
-state="$MONOLITH_STATE" \
-state-out="$TARGET_STATE" \
"$resource" "$new_address"Using -state and -state-out as separate files is critical — the monolith state is read-only throughout. If the script fails halfway, the source is intact and the migration can be restarted cleanly.
After each module is processed, the script reports a moved/skipped count. Any individual failure is logged but doesn’t abort the run — the script continues with remaining modules and gives a clear picture of what succeeded.
Finally, the script cleans up Terraform’s auto-generated .backup files:
find . -name "*.backup" -type f -deleteStep 3 — Validate Each Module
With per-module state files in place, each Terragrunt module was initialized and planned independently:
terragrunt init
terragrunt planinit pulled providers and wired the local backend to the freshly written state file. plan was the correctness gate: zero diff means the sliced state matches live infrastructure exactly. Any unexpected addition, deletion, or replacement at this stage indicates a resource address mismatch and must be resolved before proceeding.
Every module passed with no changes.
Step 4 — Apply to Materialize Outputs
Even with no infrastructure changes, each module needed an apply to write its output values into the state. Terragrunt’s dependency blocks resolve by reading outputs from a completed apply — without it, dependent modules fail at plan time with missing output errors.
terragrunt apply # no changes, but outputs are written to stateStep 5 — Validate the Full Dependency Graph
terragrunt run-all plan
terragrunt run-all applyWith all modules applied and outputs available, a full DAG plan confirmed that cross-module dependency resolution was correct end-to-end — downstream modules reading VPC IDs, RDS endpoints, and certificate ARNs from upstream modules all resolved cleanly. Again, no changes.
Step 6 — Migrate Local State to S3
Up to this point every module used a local backend. The final step switched all modules to the remote backend defined in root.hcl:
remote_state {
backend = "s3"
config = {
bucket = local.env_vars.remote_state_bucket
key = "${path_relative_to_include()}/terraform.tfstate"
region = local.env_vars.aws_region
encrypt = true
dynamodb_table = local.env_vars.remote_state_lock_table
}
}Each module gets its own S3 key derived from its directory path — isolation by convention, not per-module configuration. Switching backends required:
terragrunt init -reconfigureRun per module. Terraform detected the backend change, prompted to push the local state to S3, and migrated it. From this point, all state is remote, encrypted at rest, and protected by DynamoDB locking — one lock table entry per module.
Key Engineering Decisions
Script-driven slicing over manual commands. With 13 modules and hundreds of resources, manual terraform state mv is a procedure that will eventually produce a typo. Encoding the mapping in a script made the operation reproducible, reviewable in version control, and safe to re-run if interrupted.
Immutable source state. Using -state and -state-out as separate files throughout the script means the monolith state is never modified. If anything goes wrong, the source is intact and the migration can be restarted from scratch.
Dynamic module discovery. The script derives module names from the state list rather than requiring a hardcoded inventory. If a module exists in state but has no directory mapping, it gets a warning rather than silent omission — a built-in completeness check.
Python for address rewriting. The regex required to correctly strip nested module prefixes — including optional bracket indexes like [0] — is not safely expressible in pure bash. A Python one-liner keeps the logic correct and readable without adding external tooling dependencies.
Local backend first, S3 last. Keeping state local during slicing and validation avoids partial pushes to S3 mid-migration. The S3 switch happens only after every module has a verified clean plan and a completed apply.
Trade-offs
What was optimized: blast radius reduction, state isolation, per-module locking, and independent apply cadence. The client can now update Kubernetes deployment configuration without acquiring a lock on RDS or the VPC.
What was sacrificed: operational simplicity during the migration window. Between pulling the monolith state and completing init -reconfigure across all modules, state exists in two forms simultaneously. A brief change freeze was required to prevent drift.
Ongoing overhead: Terragrunt’s DAG and dependency blocks introduce a concept that engineers only familiar with flat Terraform need to learn. The dependency graph must be maintained as new modules are added. This is the correct trade-off — explicit dependencies beat implicit coupling — but it’s not free.
Operational Impact
Post-migration the client operates 13 independent state files in S3, each with its own DynamoDB lock, its own plan/apply cycle, and a clear ownership boundary. Adding a new infrastructure component is a new directory with a terragrunt.hcl inheriting shared config from root.hcl — not a modification to a shared monolith requiring full-stack review.
The run-all plan command still provides a global view when needed. The difference is that it’s now opt-in — a diagnostic tool rather than the only way to touch anything.
Conclusion
Migrating from a Terraform monolith to Terragrunt is primarily a state surgery problem. The infrastructure doesn’t change — only its management boundary does. The correctness guarantee is simple: a clean plan with zero diff at every module after the slice. Everything before that is tooling to make the slice accurate, safe, and repeatable. The migration script is the critical artifact — not the Terragrunt configuration, which is straightforward to write once the state is clean.
If you’re working on a similar state decomposition or evaluating Terragrunt adoption for a growing SaaS platform, feel free to reach out at hello@jakops.cloud.