· Jakub · Cloud · 6 min read
Athena Cost Kill Switch: Automated IAM Credential Revocation with CloudWatch, EventBridge, and Lambda
How I designed an automated kill switch for a client's Athena data platform that disables OpenMetadata credentials within seconds of a scan threshold breach — no human intervention required.
The Problem
The client was running a data platform on AWS Athena, exposed to OpenMetadata for schema cataloging and lineage tracking. OpenMetadata authenticates via static IAM credentials — once issued, the service operates entirely outside the platform team’s control boundary.
That’s a real exposure: a misconfigured metadata scan, a connector loop, or an aggressive schema discovery run can silently process hundreds of gigabytes of S3 data before anyone notices. Athena bills per byte scanned. AWS Budgets alerts are retrospective. There’s no native rate limiting on scan volume beyond per-query cutoffs.
The client needed an automated response — not a dashboard. I designed a kill switch: the moment Athena scan thresholds are breached on the OpenMetadata workgroup, the access key is disabled automatically, within seconds.
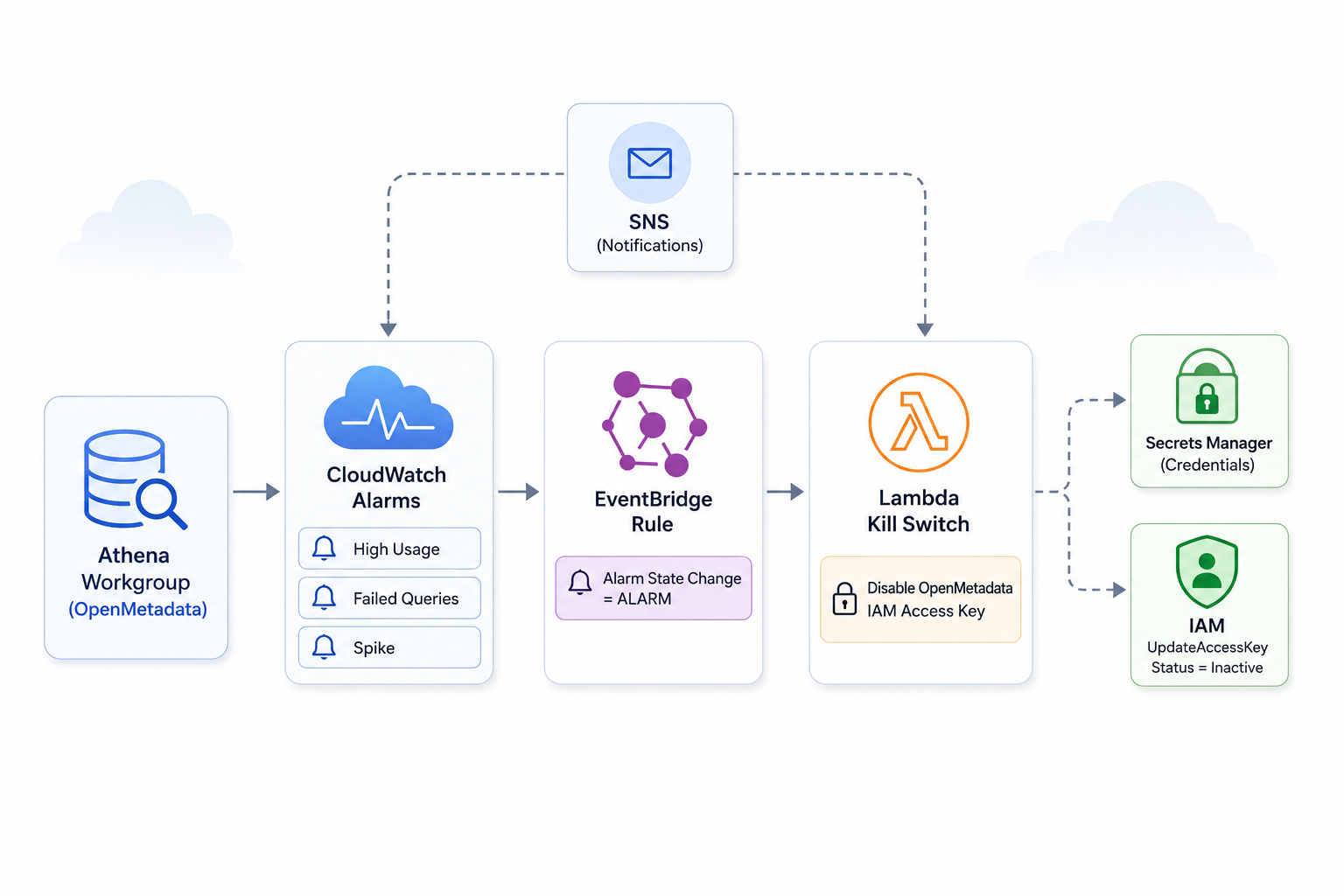
System Architecture
The solution is four layers working in sequence.
Athena Workgroups with enforced limits
Two dedicated workgroups are provisioned: one for PowerBI consumers, one for OpenMetadata. Both enforce a 1 GB per-query scan cutoff and have CloudWatch metrics publishing enabled. Separating workgroups allows alarm scoping — the kill switch targets only OpenMetadata activity, leaving PowerBI unaffected.
Three independent CloudWatch alarms
Three alarms monitor the OpenMetadata workgroup, each covering a distinct failure mode:
athena-high-usage— fires whenProcessedBytesexceeds a configurable MB threshold over a rolling window (default: 150 MB, 5-minute period, 2 evaluation periods, 1 datapoint to alarm)athena-openmetadata-failed-queries— fires when more than 5 queries fail within 5 minutesathena-openmetadata-spike— a tighter alarm: 500 MB processed within 60 seconds, 2 evaluation periods
All three publish to an SNS topic for parallel email notification.
EventBridge rule — alarm state routing
A single EventBridge rule pattern-matches on CloudWatch Alarm State Change events for all three alarm names. Any transition to ALARM state triggers the Lambda directly.
detail = {
alarmName = [
"${var.environment}-${var.project}-athena-high-usage",
"${var.environment}-${var.project}-athena-openmetadata-failed-queries",
"${var.environment}-${var.project}-athena-openmetadata-spike"
],
state = { value = ["ALARM"] }
}Lambda kill switch
The Lambda reads the OpenMetadata IAM username and access key ID from Secrets Manager (KMS-encrypted), then calls iam:UpdateAccessKey with Status = Inactive. The credential is disabled immediately. Athena queries from OpenMetadata begin failing with auth errors.
iam_client.update_access_key(
UserName=username,
AccessKeyId=access_key_id,
Status="Inactive"
)The Lambda IAM role is tightly scoped: secretsmanager:GetSecretValue on the specific secret ARN, iam:UpdateAccessKey scoped to the /service-accounts/ path, and KMS decrypt permissions. Nothing broader.
Separate S3-triggered Glue pipeline
An independent EventBridge rule watches for PutObject and CompleteMultipartUpload events on the data warehouse S3 bucket and routes to a Step Function that starts a Glue crawler. This pipeline has no shared state with the kill switch path — different event source, different target, separate IAM roles.
Runtime Behavior
Under normal operation the system is entirely passive. CloudWatch collects metrics, alarms hold in OK state, EventBridge evaluates no matches.
When a threshold is crossed:
- CloudWatch transitions an alarm to
ALARM - EventBridge routes the state-change event to Lambda — typically within seconds
- Lambda fetches credentials from Secrets Manager
- The access key is set to
Inactive
The Lambda does not re-enable the key. Recovery is a deliberate manual action: a platform engineer investigates, determines root cause, and rotates or re-activates the credential.
SNS fires in parallel, so the team receives an email notification at the same moment the automated response executes.
Key Engineering Decisions
IAM user with static credentials, not role assumption
OpenMetadata doesn’t support role assumption — it requires an access key and secret. This constrained the kill switch to credential-level revocation. Disabling the key is the fastest available response: it’s immediate, reversible, and doesn’t touch the workgroup configuration or IAM policy.
Secrets Manager over Lambda environment variables
Storing the access key ID and IAM username in Secrets Manager keeps the Lambda stateless. Credential rotation — whether scheduled or post-incident — doesn’t require a Terraform apply or a Lambda redeploy. The secret is KMS-encrypted with the same key used across the Athena stack.
Three independent alarms, one EventBridge rule
A composite alarm would require all conditions to align before firing. Three independent alarms fire on any single signal — sustained high volume, repeated failures, or a sudden spike. Each covers a different failure mode. The EventBridge rule matches on any of the three names: one rule, three triggers.
Direct EventBridge-to-Lambda, not Step Function
The Glue crawler path uses a Step Function because Glue state management benefits from orchestration. The kill switch is a single, stateless IAM API call. A Step Function would add latency and operational surface area with no benefit.
Configurable thresholds via Terraform variables
The athena_high_usage_threshold_mb and athena_high_usage_period are exposed as module variables with defaults. Per-environment tuning — tighter thresholds in staging, more relaxed in development — doesn’t require code changes.
Trade-offs
Optimized for: speed of response and operational simplicity. The kill switch fires in seconds. The Lambda is under 50 lines. There’s no orchestration layer, no state machine, no external dependency beyond IAM and Secrets Manager.
Sacrificed: self-healing. There is no automatic re-enable after a cooldown period. An alarm breach is treated as a signal requiring human review. The client’s team explicitly wanted visibility and control over re-activation — not a system that could silently re-enable a misbehaving connector.
No dead-letter queue on the Lambda: If the kill switch invocation fails — Secrets Manager throttling, IAM API error, Lambda timeout — there is no retry beyond Lambda’s built-in async retry behavior. A failed invocation is visible in CloudWatch Lambda metrics, but there’s no secondary alerting path specifically for kill switch failures.
Spike alarm fixed period: The athena-openmetadata-spike alarm uses a hardcoded 60-second period. Unlike the high-usage alarm, this is not a Terraform variable. A legitimate large schema discovery scan could trigger a false positive, and adjusting the period requires a code change rather than a variable override.
athena-high-usage alarm has no Lambda action: Looking at the current configuration, only athena-openmetadata-failed-queries and athena-openmetadata-spike send to SNS via alarm_actions. The high-usage alarm’s EventBridge routing is handled through the event rule pattern match — not a direct alarm_actions reference — which is worth noting when validating end-to-end alarm coverage.
Cost & Operational Impact
The architecture introduces negligible ongoing cost. CloudWatch alarms, EventBridge rules, and Lambda invocations are event-driven and low-frequency. In a healthy system the Lambda never runs.
The operational leverage is asymmetric: a targeted Terraform module and a small Python function replace what would otherwise require on-call manual response to a cost spike, or investment in third-party query governance tooling.
The client’s team retains full visibility through SNS notifications while eliminating the response window between a threshold breach and human intervention.
Conclusion
This kill switch pattern — CloudWatch alarm → EventBridge → Lambda credential revocation — is a lightweight but production-grade approach to cost control on managed query services. It works because the risk surface is well-defined: one IAM user, one set of credentials, one external service operating outside the platform boundary.
The key insight is that automated cost control on Athena doesn’t require a policy engine or a governance platform. It requires clearly defined thresholds, fast event routing, and a kill action that’s cheap to execute and reversible only by a human.
If you’re working on similar infrastructure challenges around AWS cost control, data platform access governance, or IAM-level automation, feel free to reach out at hello@jakops.cloud.